What is Kube-Proxy and Why Move from iptables to eBPF?
#kubernetes#networking#ebpf#cilium#kube-proxy#iptables#devops#system-design
Every Kubernetes cluster runs kube-proxy on each node (unless you deliberately replace it). It implements the Service virtual IP abstraction: stable ClusterIP and DNS names on top of pods that constantly start, stop, and change IP. For years the default dataplane has been iptables—netfilter rules that DNAT traffic to backend pods. That design works in small clusters but becomes a scalability and update-latency bottleneck as services and endpoints grow.
This post explains what kube-proxy does, how iptables mode forwards packets, why teams move to eBPF (often via Cilium), and what changes operationally when kube-proxy is replaced.
Source: Content and diagrams adapted from Isovalent – What is Kube-Proxy and why move from iptables to eBPF? (Jeremy Colvin, 2023) and Remove kube-proxy with Cilium.
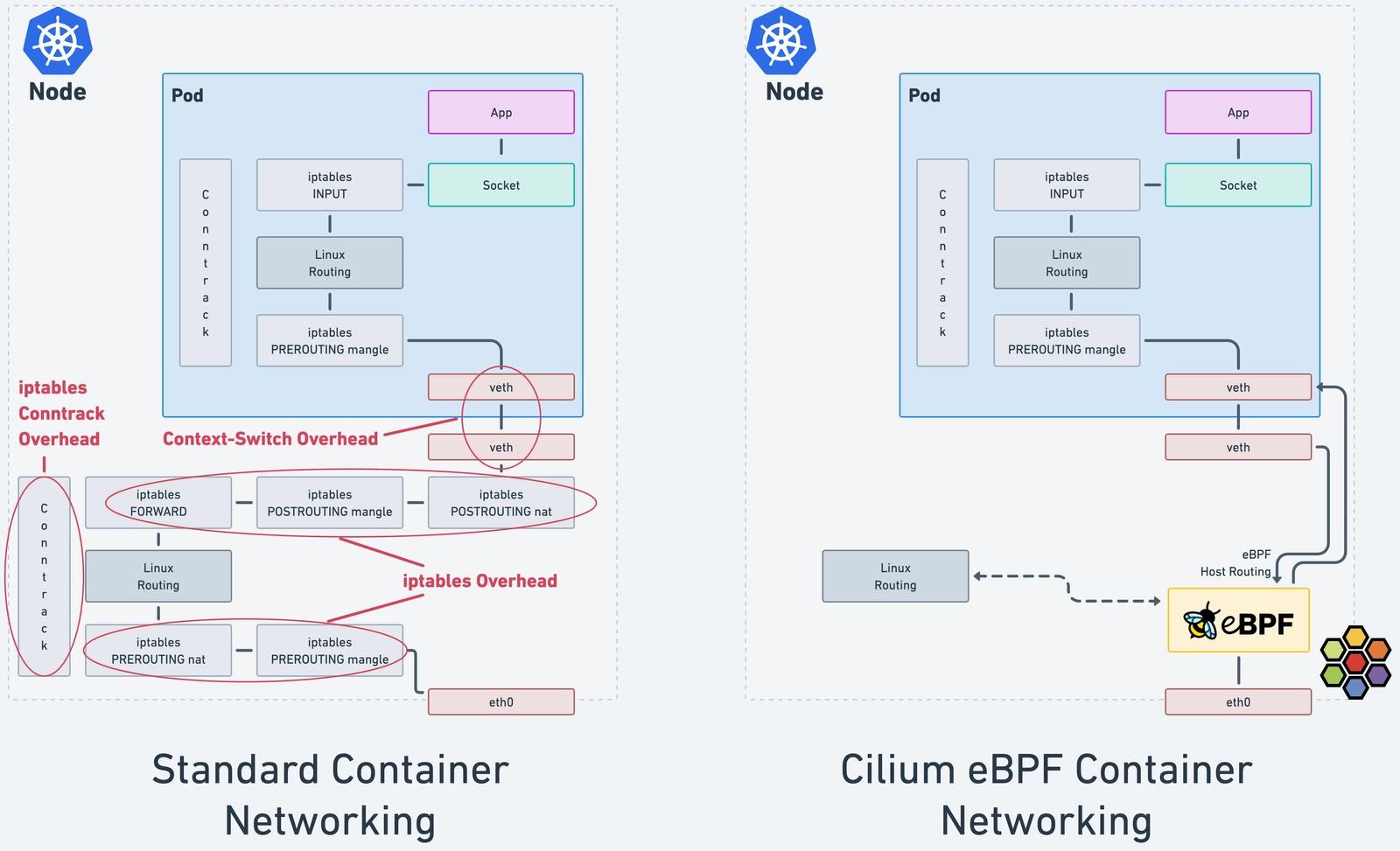
The problem kube-proxy solves
Pods are ephemeral. Their IPs change on every reschedule. Applications need:
| Need | Kubernetes answer |
|---|---|
| Stable address | Service ClusterIP (virtual IP) |
| Stable name | CoreDNS → my-svc.my-ns.svc.cluster.local |
| Load spread | kube-proxy (or replacement) picks a backend pod |
Without a proxy layer, every client would need to watch the API for endpoint changes and maintain its own backend list—impractical for most apps. DNS round-robin alone is insufficient because many clients cache DNS aggressively and TTL behavior is inconsistent (Kubernetes docs).
Pod (client) Service (stable) Backends (dynamic)
+-----------+ +----------------+ +-------+ +-------+
| app | curl backend:80 | ClusterIP | proxy | pod-A | | pod-B |
| |------------------>| 10.96.0.10:80 |--------->| :8080 | | :8080 |
+-----------+ +----------------+ +-------+ +-------+
^
|
kube-proxy programs
forwarding rules on
every node
What is kube-proxy?
kube-proxy is a DaemonSet (or static pod) on every node. It:
- Watches the API server for
ServiceandEndpointSliceobjects. - Programs the node’s packet forwarding path so traffic to a Service IP:port reaches a chosen endpoint.
- Re-syncs when endpoints change (scale up/down, rolling deploy).
Supported modes on Linux (official reference):
| Mode | Mechanism | Notes |
|---|---|---|
| iptables | netfilter iptables rules | Historical default; sequential rule chains |
| ipvs | Kernel IPVS + iptables | Hash-based LB; deprecated path in newer K8s |
| nftables | netfilter nftables API | Recommended kube-proxy evolution on modern kernels |
| eBPF (Cilium KPR) | Cilium replaces kube-proxy entirely | Not a kube-proxy mode—separate CNI dataplane |
On Windows, kube-proxy uses kernelspace mode.
How iptables mode works
In iptables mode, kube-proxy installs NAT rules in the kernel netfilter subsystem. When a new Service appears:
- Rules redirect traffic destined for the virtual ClusterIP to a per-service chain.
- Per-service chains point to per-endpoint rules.
- Endpoint rules perform DNAT to a real pod IP:port.
- A backend is chosen (random or sessionAffinity: ClientIP).
Packet: dst=10.96.0.10:80 (Service VIP)
|
v
+-------------------------------------------+
| KUBE-SERVICES chain |
| match VIP:port -> jump KUBE-SVC-XXXXX |
+----------------------+--------------------+
|
v
+-------------------------------------------+
| KUBE-SVC-XXXXX (per Service) |
| pick backend (probabilistic / affinity) |
+----------------------+--------------------+
|
+------------+------------+
| |
v v
+------------------+ +------------------+
| KUBE-SEP-AAA | | KUBE-SEP-BBB |
| DNAT -> pod-A | | DNAT -> pod-B |
+------------------+ +------------------+
Per-connection behavior: Once a TCP connection is established to a backend, subsequent packets in that flow follow the same NAT binding. New connections are distributed across endpoints (approximately random in iptables mode).
NodePort / LoadBalancer: Same core flow; for NodePort and external LBs the client source IP may be altered (SNAT) depending on path—important for logging and policy.
Why iptables/kube-proxy struggles at scale
iptables was designed for smaller, more static networks. Kubernetes is the opposite: thousands of pods, frequent endpoint churn, and continuous rule updates.
1. Rule count grows with services × endpoints
Kubernetes docs note that iptables mode creates multiple rules per Service and per endpoint IP. In clusters with tens of thousands of pods:
- iptables chains become very long.
- kube-proxy sync can take seconds when many EndpointSlices change at once.
- CPU spikes during full or partial rule rewrites.
Cluster growth
|
v
Services -----> more KUBE-SVC-* chains
+
Endpoints -----> more KUBE-SEP-* rules per service
|
v
Longer linear walks + slower sync_proxy_rules
2. Sequential rule matching (O(n) feel)
Each packet may traverse many iptables rules before a match. As chains grow, per-packet cost increases. At large scale this shows up as higher node CPU, latency, and noisy neighbor effects on busy nodes.
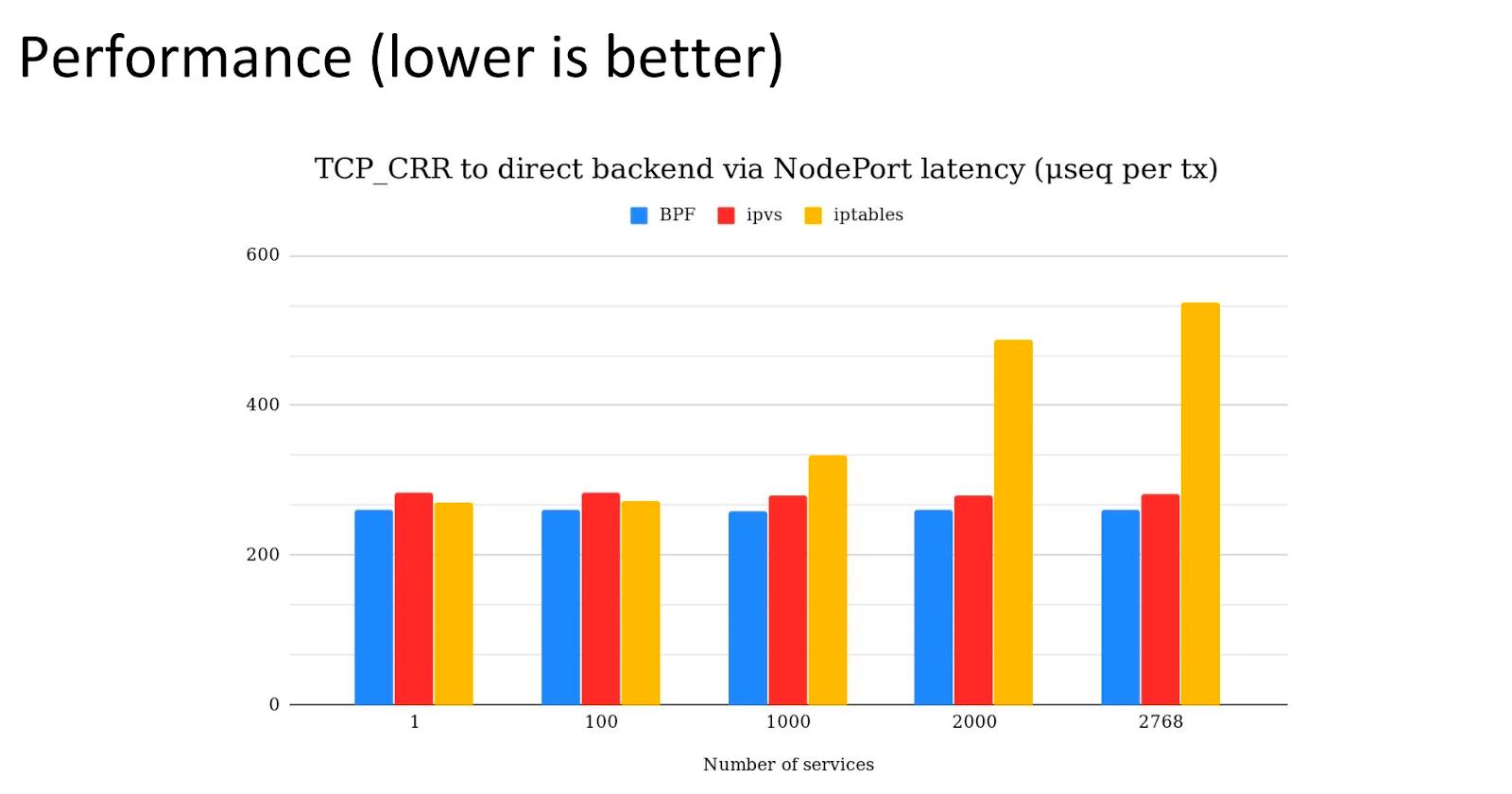
3. Update model: rewrite chains on change
When endpoints change (e.g. delete a Deployment with 100 pods), kube-proxy must update iptables. Tuning minSyncPeriod and syncPeriod trades aggregation vs staleness (Kubernetes iptables tuning). Even with improvements since Kubernetes 1.28, the fundamental model is many discrete rules maintained by a userspace controller.
4. Limited observability
iptables/kube-proxy does not emit rich per-flow telemetry. Debugging “which backend did this connection hit?” or “why was this packet dropped?” often requires tcpdump, conntrack, or external tools.
| Symptom at scale | Typical cause |
|---|---|
| Slow rollouts / endpoint lag | kube-proxy still syncing iptables |
High sync_proxy_rules_duration | Large rule churn |
| Elevated node CPU on traffic spikes | Per-packet rule traversal |
| Hard-to-debug service routing | No first-class flow visibility |
Evolution inside kube-proxy: IPVS and nftables
Before jumping to eBPF, Kubernetes added other kube-proxy backends:
IPVS mode
IPVS uses a kernel hash table for load balancing—better than pure iptables chains for some large clusters. However, the IPVS API did not map cleanly to every Kubernetes Service edge case; IPVS mode is deprecated in favor of nftables on supported kernels (Kubernetes 1.35+ notes).
nftables mode
nftables is the modern netfilter API and is the recommended kube-proxy path on Linux when you stay on kube-proxy but want better performance than legacy iptables. It is still rule-oriented compared to a purpose-built eBPF service map.
| Approach | Lookup model | Still kube-proxy? |
|---|---|---|
| iptables | Chains of rules | Yes |
| ipvs | Kernel hash (LB) | Yes (deprecated) |
| nftables | nftables rulesets | Yes |
| Cilium KPR | eBPF maps + programs | No (kube-proxy disabled) |
What is eBPF (in this context)?
eBPF (extended Berkeley Packet Filter) lets you run verified programs in the Linux kernel at hook points (XDP, TC, cgroup, socket). Programs can use BPF maps (hash tables, arrays) for O(1) lookups and update state atomically without reloading huge iptables chains.
For Kubernetes networking, eBPF enables:
- Service load balancing via maps (
vip:port→ backends). - Network policy without iptables rule explosion.
- Observability (flows, DNS, HTTP) from the dataplane.
- Socket-level redirection at
connect()time in some designs.
Cilium, originally built by kernel/eBPF maintainers, is the most widely adopted eBPF CNI that can replace kube-proxy entirely.
Replacing kube-proxy with eBPF (Cilium KPR)
Kube-proxy replacement (KPR) means Cilium implements Service, NodePort, and LoadBalancer forwarding—kube-proxy is not deployed.
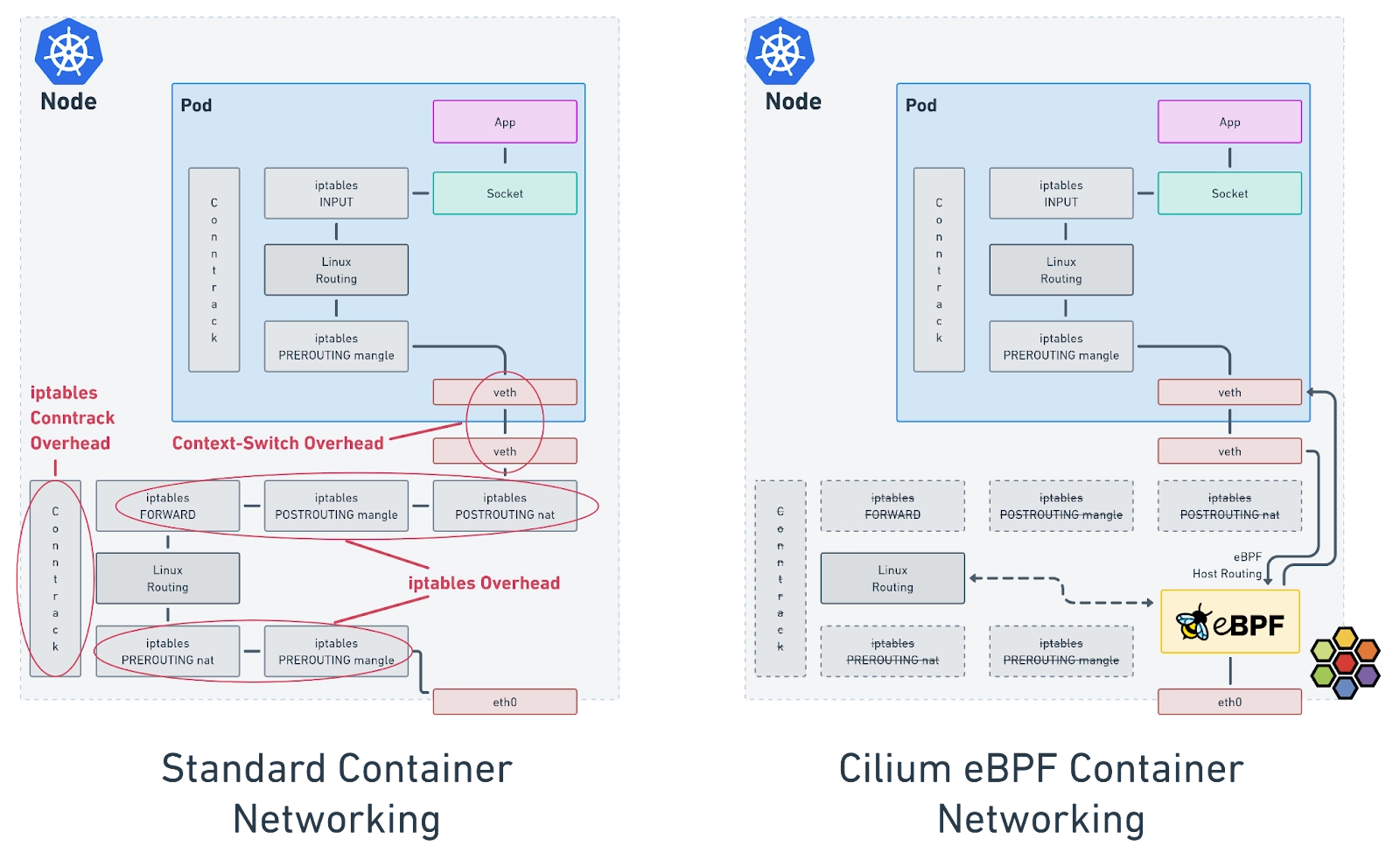
BEFORE (iptables kube-proxy) AFTER (Cilium eBPF)
API -> kube-proxy -> iptables API -> Cilium agent -> BPF maps
| |
v v
per-packet DNAT rule walk hash lookup + socket redirect
O(chains) update on change atomic map entry update
Datapath comparison
| Aspect | kube-proxy (iptables) | Cilium eBPF (KPR) |
|---|---|---|
| Service lookup | Sequential iptables chains | BPF hash map lookup |
| Rule updates | Rewrite/sync chains | Atomic map updates |
| East-west LB | Per-packet DNAT (typical) | Often socket-level at connect() |
| Observability | Minimal | Hubble (L3/L4/L7 flows) |
| Policy | Separate CNI / NetworkPolicy backend | Integrated eBPF policy |
| Masquerading | iptables MASQUERADE | eBPF masquerade (configurable) |
Example BPF map roles (conceptual)
Cilium maintains maps such as (names vary by version):
| Map purpose | Role |
|---|---|
lb4_services | Service VIP:port → service ID, flags |
lb4_backends | Backend pod addresses and weights |
lb4_reverse_sk | Socket cookies for established connections (optimize return path) |
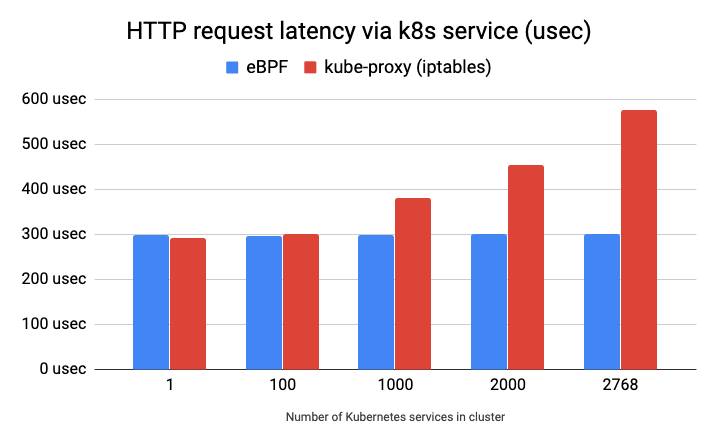
What kube-proxy expressed as hundreds of iptables chains becomes hash table entries with near-constant lookup time regardless of service count (Cilium / eBPF networking overview).
Socket-level load balancing
A major optimization: instead of DNAT on every packet, Cilium can rewrite the destination at connect() time in the socket layer. The application’s first packet already targets the chosen pod—reducing per-packet NAT overhead on east-west traffic.
Traditional DNAT path:
app -> send many packets -> each packet hits iptables -> pod
Socket-level path:
app -> connect() -> eBPF picks backend -> socket bound -> packets go direct
XDP and north-south traffic
For NodePort and external load balancing, Cilium can attach XDP (eXpress Data Path) programs for very early packet handling—useful for high-throughput ingress and features like Direct Server Return (DSR) while preserving client source IP for observability (Isovalent scalable LB).
Benefits of moving to eBPF
Performance and scale
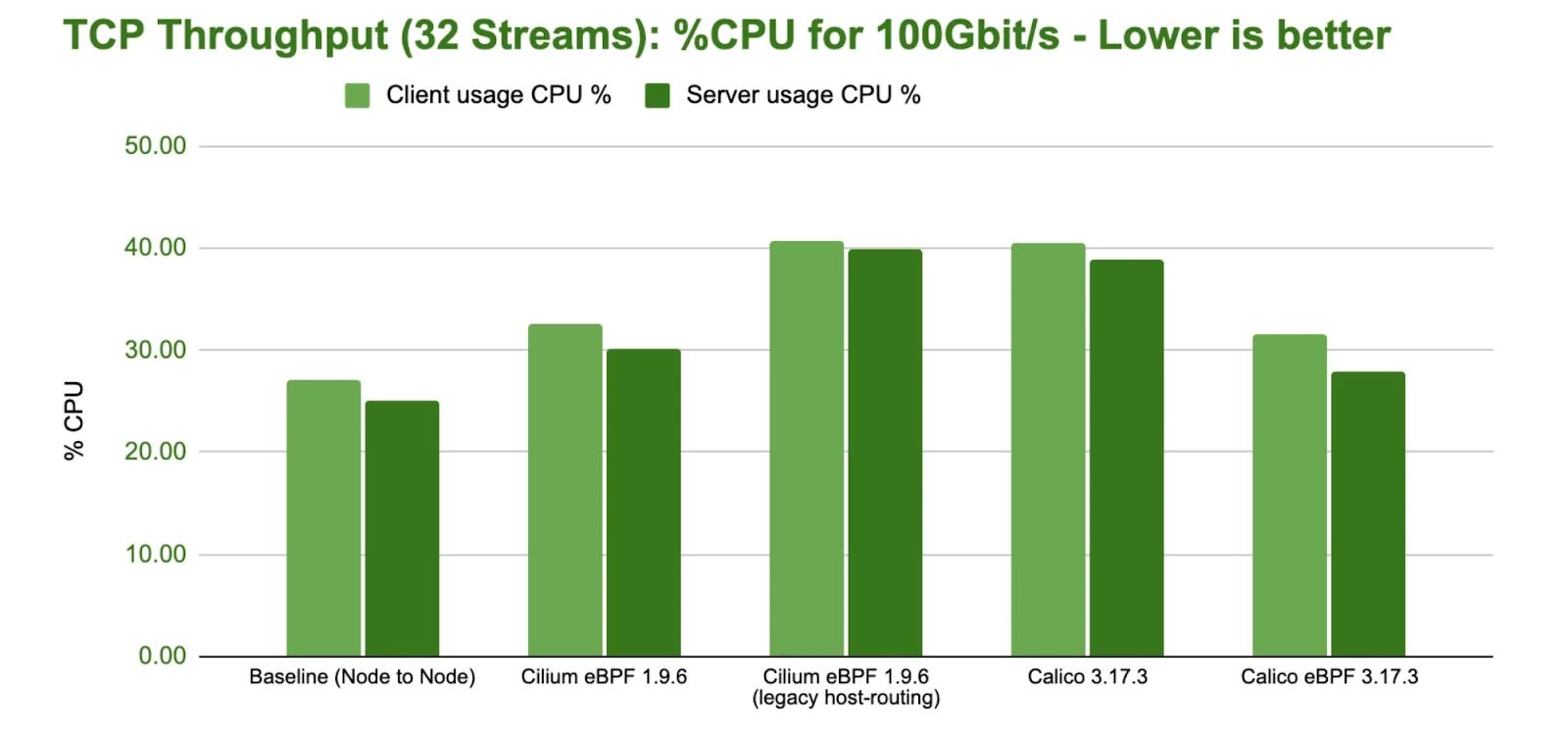
- Faster service updates when pods churn (rolling deploys, HPA).
- Lower CPU on busy nodes by avoiding long iptables walks.
- Predictable lookup cost as service count grows (hash maps vs chains).
Operations and debugging
- Hubble provides flow-level visibility: which pod talked to which service, DNS, HTTP metadata.
- Clearer correlation between control plane events (EndpointSlice change) and datapath state (BPF map).
Unified dataplane
With Cilium you often get in one stack:
- CNI pod networking
- Service LB (kube-proxy replacement)
- Network policy (L3/L4/L7)
- Optional service mesh features without a sidecar per pod in some cases
Where it is used in production
eBPF/Cilium is the default or supported dataplane on several major platforms (e.g. GKE Dataplane V2, EKS with Cilium, AKS Azure CNI powered by Cilium variants—check your cloud’s current offering). Adoption is strongest when teams need scale, policy, and observability in one CNI.
KPR deployment modes (Cilium)
| Mode | Behavior |
|---|---|
| Full kube-proxy replacement | Disable kube-proxy; Cilium handles ClusterIP, NodePort, LoadBalancer |
| Partial | Cilium replaces NodePort/HostPort only; coexist with kube-proxy (legacy / constrained kernels) |
| kube-proxy only | Traditional; Cilium as CNI without KPR |
Production recommendation: full replacement on supported kernel versions (modern Linux with BTF-enabled kernels—verify Cilium’s version matrix for your distro).

Migration checklist
- Kernel and Cilium version — Confirm eBPF, BTF, and KPR support on your node OS.
- Disable kube-proxy — Remove DaemonSet or set
kubeProxyReplacement: true(Helm values vary by chart version). - Validate Service types — ClusterIP, NodePort, LoadBalancer,
externalTrafficPolicy: Local, session affinity, UDP. - Check assumptions — Tools that parse iptables
KUBE-*chains will see different state; use Hubble/metrics instead. - Load test — Measure sync latency during large rollouts and CPU under peak QPS.
- Rollback plan — Keep a path to re-enable kube-proxy if a rare Service edge case appears.
Migration flow
assess kernel/Cilium -> deploy Cilium CNI -> enable KPR
-> disable kube-proxy -> soak test -> cutover traffic
When to stay on kube-proxy (for now)
iptables or nftables kube-proxy may be fine when:
- Small clusters, modest service/endpoint counts.
- Managed Kubernetes defaults and you cannot change CNI.
- Team lacks eBPF operational experience and SLAs are met today.
- Strict compliance requires approved components only.
Consider eBPF/KPR when:
sync_proxy_rules_durationor endpoint lag hurts deploy velocity.- Node CPU from networking grows with cluster size.
- You need flow-level observability and L7 policy without heavy sidecar mesh.
- You are standardizing on Cilium for CNI anyway.
Summary
| Topic | Takeaway |
|---|---|
| kube-proxy | Per-node controller that implements Kubernetes Services via kernel forwarding rules. |
| iptables mode | DNAT chains per service/endpoint; simple but costly at scale. |
| Scale pain | Rule count, sync latency, per-packet chain walks, weak observability. |
| nftables kube-proxy | Better kube-proxy backend on modern Linux; still rule-based. |
| eBPF / Cilium KPR | Replaces kube-proxy; service state in BPF maps; socket-level LB; Hubble visibility. |
| Why move | Performance, faster updates, unified policy/observability—not because iptables is “wrong” for every cluster. |
kube-proxy made Kubernetes Services work everywhere. eBPF is how many teams keep that abstraction at cloud-native scale—without carrying twenty years of netfilter chain growth on every packet.
Further reading
Diagrams in this post are from the Isovalent iptables → eBPF article and Remove kube-proxy with Cilium.
- Isovalent – What is Kube-Proxy and why move from iptables to eBPF?
- Isovalent – Remove the Chains of Kube-Proxy: Going Kube-Proxy free with Cilium
- Kubernetes – Virtual IPs and Service Proxies
- Cilium documentation – Kube-proxy replacement
- Isovalent – Scalable Load Balancing and Ingress
- Related on this site: Kubernetes (k8s) notes · Istio and dataplane capture
Comments