CAP Theorem in System Design: Consistency, Availability, and Partition Tolerance
#system-design#distributed-systems#databases#architecture#devops#interview
The CAP theorem states that in a networked shared-data or distributed system, you can guarantee at most two of three properties at the same time: Consistency (C), Availability (A), and Partition tolerance (P). It is a mental model for trade-offs when designing databases, caches, and multi-region services—not a law that forbids all three in every situation, but a clear framing for what breaks when the network fails.
This post covers the three properties, how CA, CP, and AP systems differ, a worked partition example, and practical use cases (banking, social feeds, shopping carts). Diagrams are included throughout.
What the CAP theorem says
In any distributed system that stores shared state:
- The theorem provides a way to think about trade-offs when building and operating such systems.
- It helps explain why certain databases or architectures fit certain use cases.
- Under a network partition, a system must choose between strong consistency and full availability for conflicting reads/writes—you cannot have both guarantees in the classic sense.
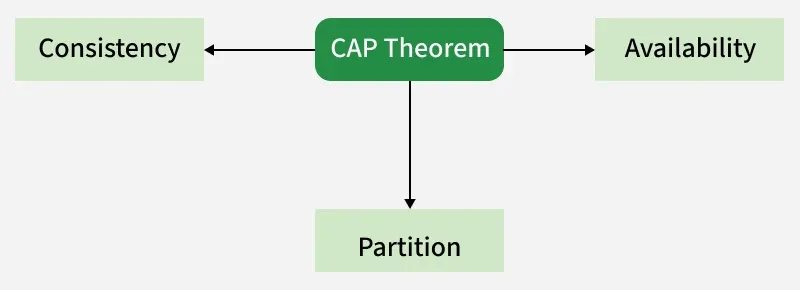
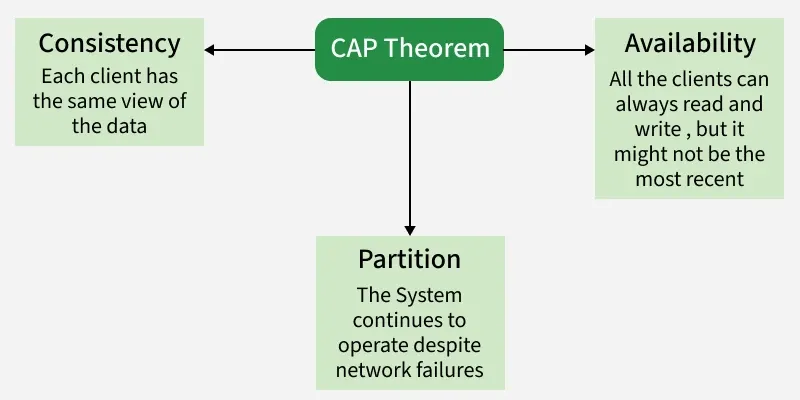
| Guarantee | One-line meaning |
|---|---|
| C – Consistency | Every client sees the same data at the same time (or linearizable / agreed model). |
| A – Availability | Every non-failing node responds to reads and writes within bounded time. |
| P – Partition tolerance | The system keeps operating despite arbitrary message loss or unreachable nodes. |
In practice, partitions happen on real networks (cable cuts, AZ failures, misconfigured routes). So most production distributed systems assume P and trade between C and A during a partition.
The three properties
1. Consistency
Consistency means all clients see the same data at the same time, no matter which node they connect to. In weaker forms (e.g. eventual consistency), clients are guaranteed to converge to the same state at some point in the future, but not necessarily immediately after a write.
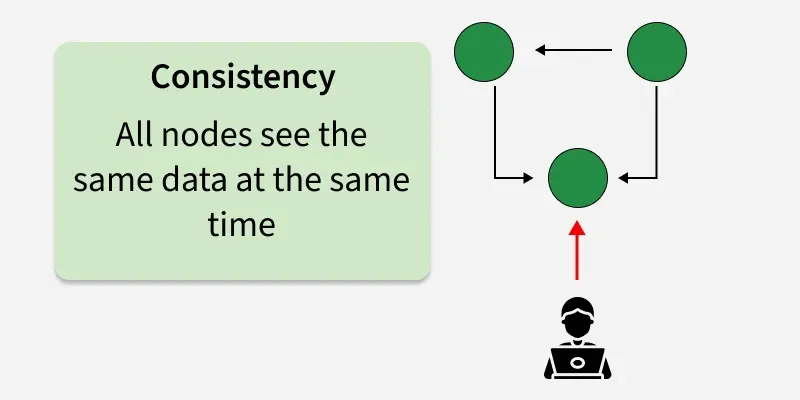
In the diagram above:
- All nodes in the system see the same data at the same time because replicas communicate and share updates.
- A change on one node is propagated to all other nodes so everyone has up-to-date information (under a strong consistency model).
Strong vs eventual:
| Model | Behavior |
|---|---|
| Strong / linearizable | After a successful write, all reads return the new value (or an equivalent globally ordered view). |
| Eventual | Replicas may temporarily diverge; given no new writes, they eventually agree. |
2. Availability
Availability means every non-failing node in the distributed system returns a response for every read and write request within a bounded amount of time, even when other nodes are down or unreachable.
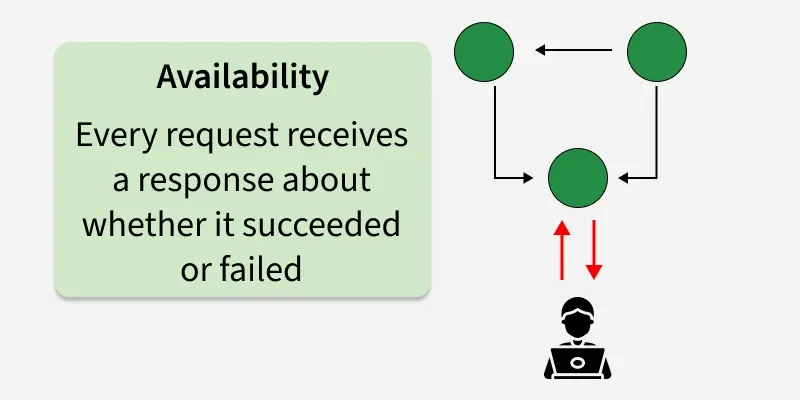
In the diagram above:
- Clients send requests; the system remains up and responds.
- Every request gets a response (success or explicit error)—users always get feedback, which is central to availability as usually defined in CAP discussions.
Availability does not mean “every operation succeeds”; it means the system does not hang waiting indefinitely (e.g. blocking forever during a partition to preserve consistency).
3. Partition tolerance
Partition tolerance means the system continues to operate despite arbitrary message loss or failure in parts of the network. Systems designed for partition tolerance can recover when connectivity returns.
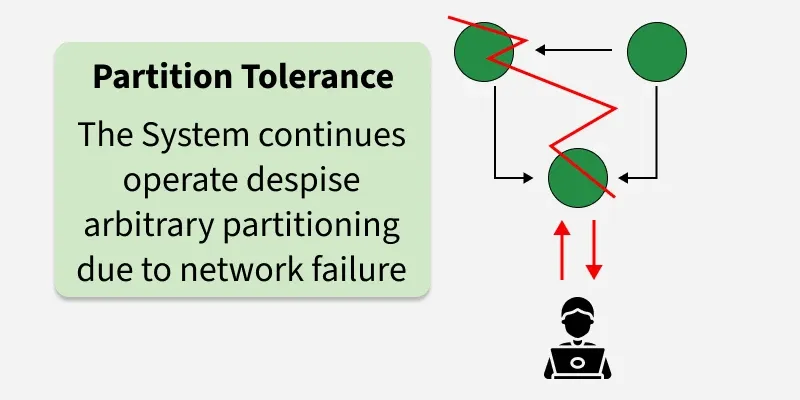
In the diagram above:
- Network failures can split nodes into groups that cannot talk to each other.
- A partition-tolerant design does not assume a single failure-free network; it handles unpredictable splits without total system collapse.
Trade-offs: CA, CP, and AP
The CAP theorem is often summarized as: pick two of C, A, and P. When a partition occurs, the meaningful choice is usually between consistency and availability.
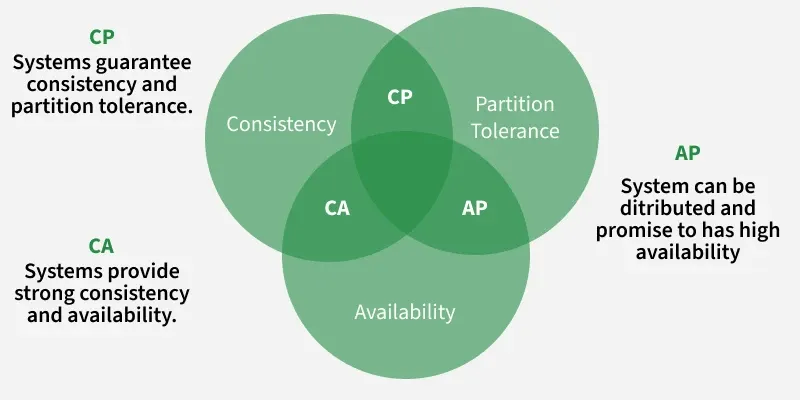
| Type | Guarantees | Sacrifices | Typical context |
|---|---|---|---|
| CA | Consistency + Availability | Partition tolerance | Single data center, stable LAN; partition ⇒ system may stop or behave incorrectly |
| CP | Consistency + Partition tolerance | Availability during partition | Financial ledgers, strong replica sets |
| AP | Availability + Partition tolerance | Immediate consistency | Feeds, carts, metrics; eventual consistency |
CA systems
A CA system provides Consistency and Availability but does not tolerate network partitions in the CAP sense: all nodes return the same data and stay accessible, but if the network splits, the system may not continue operating correctly across both sides.
Example: Traditional relational databases in a single data center with a stable network are often treated as CA: partitions are rare enough that the design optimizes for C and A locally.
CP systems
A CP system provides Consistency and Partition tolerance but may sacrifice availability during a partition. When nodes cannot communicate, the system may reject or block requests so replicas do not diverge in conflicting ways.
Examples: MongoDB (default replica set behavior in many setups), HBase—systems that prefer correct, consistent data over serving every request during a split.
During a partition:
Client Partition Client
| | | |
v | | v
+------+ X no link X | | +------+
| Node |<--------------------| |---->| Node |
| A | | | | B |
+------+ | | +------+
| | | |
| write OK | | | read may FAIL or block
| (leader / quorum) | | | (to preserve consistency)
AP systems
An AP system provides Availability and Partition tolerance but does not guarantee immediate consistency. During a partition, both sides may accept reads and writes; clients may see stale data until replication catches up.
Examples: Apache Cassandra, Amazon DynamoDB (configurable, but often used in AP-style modes)—systems that prefer staying up and reconciling later.
Worked example: partition forces C vs A
This example shows why you cannot have both strong consistency and full availability across a partition when replicas hold shared mutable state.
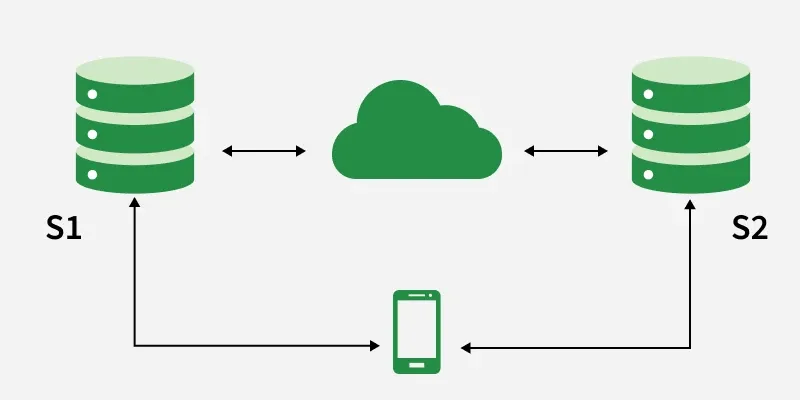
Setup:
- Two servers S1 and S2 can normally communicate; the system is partition tolerant (designed for network failure).
- A network failure isolates S1 from S2.
- A client writes to S1, then reads from S2.
If the system chooses consistency (CP behavior):
- S2 does not have the write from S1 and must not return a stale value as if it were current.
- The read on S2 must fail or block until consistency can be restored → availability is sacrificed for that request.
If the system chooses availability (AP behavior):
- S2 responds to the read (possibly with old data).
- S1 and S2 temporarily have different views → consistency is sacrificed until sync.
That is the core CAP argument: under partition, C and A conflict for this class of designs.
Before partition After partition
S1 <--------> S2 S1 X S2
same view divergent views
Write x=1 to S1 Read x from S2
CP: deny / wait
AP: return stale x (e.g. 0)
Real-world use cases
1. Banking transactions (CP)
Problem: A teller or API updates an account balance. Incorrect or duplicated balances are unacceptable.
Why CP fits:
- Consistency: Every transaction must be reflected accurately across replicas (no double spend, no lost debit).
- Partition tolerance: Branches or regions can lose connectivity; the system must not silently corrupt balances.
- Trade-off: During severe partitions, some operations may time out or be rejected rather than return a wrong balance.
| Requirement | CAP emphasis |
|---|---|
| Correct balance everywhere | C |
| Survive network splits safely | P |
| User always gets instant success | Often sacrificed under partition |
2. Social media newsfeed (AP)
Problem: Users expect the feed to load quickly; slight delay or ordering differences across devices are tolerable.
Why AP fits:
- Availability: Feeds load even if part of the network or a shard is degraded.
- Partition tolerance: Regional outages should not take down the entire product surface.
- Trade-off: A post might appear on one device slightly before another until replication completes (eventual consistency).
| Requirement | CAP emphasis |
|---|---|
| Feed always loads | A |
| Works during partial outages | P |
| Identical ordering on all devices instantly | Relaxed |
3. Online shopping cart (hybrid)
Problem: Browsing and checkout have different risk profiles.
Hybrid approach:
| Phase | Typical CAP lean | Rationale |
|---|---|---|
| Add to cart | AP | Uninterrupted browsing; temporary inconsistency on item count is acceptable. |
| Checkout / payment | CP | Order total and inventory must be consistent before charging; use transactions, locks, or quorum. |
The system must switch modes at the right boundary: optimistic, available behavior while shopping; strict consistency when money and inventory are committed.
User journey
Browse / add items ---------> Checkout / pay
| |
AP (available cart) CP (consistent order)
CAP in interviews and design reviews
Common clarifications:
- CAP is about behavior during a partition, not “you can never have all three ever.”
- Consistency in CAP is closer to linearizability / unanimous agreement than to “ACID C” in a single database—read the definition your interviewer uses.
- Many systems offer tunable consistency (e.g. read concern levels, quorum reads/writes) to slide along the C–A spectrum.
- PACELC extends the idea: if there is no partition, you still trade latency (L) vs consistency (C).
Questions to ask when choosing:
- What happens if two replicas disagree after a partition—which answer is worse: wrong data or no response?
- Is eventual consistency acceptable for this feature?
- Can we use quorum, leader election, or CRDTs to narrow the trade-off?
Summary
| Topic | Takeaway |
|---|---|
| CAP | Distributed shared-state systems: at most two of C, A, P; under partition, often trade C vs A. |
| Consistency | All clients see the same data (strong) or eventually converge (eventual). |
| Availability | Non-failing nodes respond in bounded time; no indefinite blocking. |
| Partition tolerance | System operates and recovers despite network splits. |
| CA | C + A in a non-partitioned or single-site mental model. |
| CP | C + P; may reject traffic during partition (banking, strong replicas). |
| AP | A + P; may return stale data (feeds, wide-column stores). |
| Hybrid | Different phases (cart vs checkout) can choose different trade-offs. |
Understanding CAP helps you pick storage, replication, and failure-handling patterns that match product requirements instead of treating “distributed” as a single default.
Further reading
- GeeksforGeeks – CAP Theorem in System Design (original article and diagrams)
- Martin Kleppmann, Designing Data-Intensive Applications — consistency, replication, and partitions in depth
Comments